
Steve Vigdor, April 10, 2023
I. A Very brief history of Ai
Artificial intelligence (AI) computer systems seem to be everywhere these days. The current fascination has been triggered by a recently released round of publicly accessible chatbots: OpenAI’s ChatGPT, Microsoft’s Bing AI, and Google’s Bard. These are AI systems able to understand, communicate and convey information to users in fluent everyday human language and to take over some mundane human tasks. But AI systems are also at the center of attempts to produce self-driving cars and human facial recognition, among many other applications. AI is by now a very broad field, too broad to cover all of its facets here. My goal in this post is to describe, without great detail, how AI works and advances in several of its most prominent applications, and to evaluate whether the present state of AI should be thought of as smart or dangerous. I will also describe the ongoing path to the future of AI, a future that has been variously presented as a likely state of ecstasy or apocalypse.
The conception of artificial intelligence has been with us nearly as long as computers themselves. The British mathematician Alan Turing, fresh from his achievements in using a computer to decipher German coded communications during World War II and in developing early computer systems, presented his conception of the future of computation in a 1950 paper entitled Computing Machinery and Intelligence. In this paper he asked why computers should not be able to apply reason and available information to solve problems and make decisions as accurately, but at much greater speed, as a human. He devised the so-called Turing test, or “Imitation Game,” of a computer’s ability to simulate a human and fool an interrogator sitting in a separate, isolated room.
What followed was an era of unbridled optimism poorly matched to the actual technical capabilities of early computers. Attempts to design computer systems that could “think” like a human and understand human language were funded by the RAND Corporation and later by the U.S. Defense Advanced Research Projects Agency (DARPA). John McCarthy, a computer scientist from MIT and later Stanford University, and Marvin Minsky, a co-founder of MIT’s Media Lab, played intellectual leadership roles in encouraging these efforts. Together with Nathaniel Rochester and Claude Shannon, they coined the term “artificial intelligence” and hosted a 1956 Dartmouth Summer Research Project on Artificial Intelligence that launched the field (see Fig. I.1). In 1970 Minsky told Life Magazine, “from three to eight years we will have a machine with the general intelligence of an average human being.” While significant advances were indeed made in the 1960s and 1970s on concepts for training computers, those concepts have really not come to fruition until the current century. As we will discuss in section II, it took until 1997 until IBM’s Deep Blue computer was able to master the narrow task of playing chess well enough to beat the world chess champion Gary Kasparov.

It is clear that the holy grail for these early pioneers was to achieve computers that could out-think, out-reason, and out-calculate humans on the whole host of problems that humans consider. That goal is usually described as artificial superintelligence (ASI), and we still remain a very long way from approaching that goal. The somewhat less ambitious goal of designing AI agents (computers, robots, etc.) that can learn, perceive, understand, and function completely like a human being – i.e., to be indistinguishable from humans in updated versions of a Turing test — is referred to as artificial general intelligence (AGI), and we are still slightly short of that goal. All the current examples to be described in this post fall under the rubric of artificial narrow intelligence (ANI), where the enormous hardware advances of recent decades in computational speed, memory, and storage, coupled with the digitization and online availability of huge swaths of human knowledge, have finally enabled the application of machine learning techniques envisioned during the last century to master important, but still narrowly focused, simulations of human capabilities. The variety of these narrow applications is summarized in Fig. I.2.
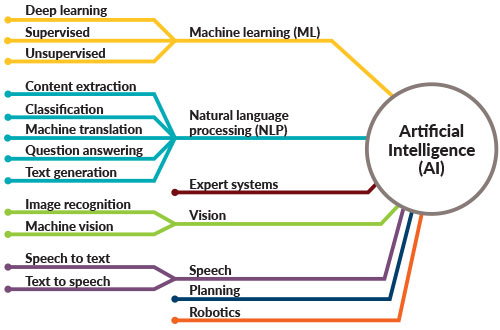
In Part I of this post, I will deal with narrow applications of AI to mastering games of skill, with the aid of machine learning and deep learning techniques, to machine image recognition, and to self-driving cars. In Part II, I will describe interactions with and comments on the latest round of chatbots, which can be viewed as a jumping-off point to the development of AGI. I will describe possible future paths to the development of AGI and ASI and offer some opinions on that future.
It is important to note that the “holy grail” of ASI scares the hell out of many deep thinkers and also of some politicians. They are alert to the frequent science fiction theme of ASI entities eventually wiping out less functional and less adaptable humans, to take over as the dominant “species” on Earth. The great theoretical physicist Stephen Hawking, before he died in 2018, said the following (see Fig. I.3) about the potential for runaway ASI: “The development of full artificial intelligence could spell the end of the human race. It would take off on its own, and redesign itself at an ever increasing rate…Humans, who are limited by slow biological evolution, couldn’t compete, and would be superseded.” Elon Musk, one of the pioneers of self-driving car manufacture and one of the original backers of OpenAI, has opined that “AI is one of the biggest risks to the future of civilization.” Musk and Apple co-founder Steve Wozniak are among 1100 technologists and AI researchers who recently signed an open letter requesting a temporary moratorium on the development of AGI. The letter says that AI decisions “must not be delegated to unelected tech leaders” and that AI systems more powerful than the current ChatGPT-4 should only “be developed once we are confident that their effects will be positive and their risks will be manageable.” Many tech leaders in the AI development world, however, share the ecstatic vision of futurist Ray Kurzweil (himself a student of Marvin Minsky), who envisions a future Singularity in which the human species will merge with much more powerful and rapidly improving AI systems to create a super-species in the not distant future. According to Kurzweil’s 2005 prediction: “I set the date for the Singularity—representing a profound and disruptive transformation in human capability—as 2045.”

Frequent depictions of AI in the popular culture run the gamut from wonder to fear: from the sensitive, but super-intelligent personal smart phone assistant Samantha in Spike Jonze’s movie Her, to the loving but misunderstood child humanoid David in Steven Spielberg’s movie A.I., to the replicants barely distinguishable from humans in Ridley Scott’s Blade Runner, to the sentient robot Ava clever enough to outwit and escape from her creator in Alex Garland’s Ex Machina, to the malevolent control computer HAL in Stanley Kubrick’s 2001: A Space Odyssey.
Even the narrow AI we currently see in many aspects of life has considerable possibilities for abuse, as we will note in this post, and the European Union is considering initial government regulations, while the U.S. Congress has as yet made no attempts to regulate, despite concerns of some members. EU legislation would “require A.I. companies to conduct risk assessments of their technology — and violators could be fined up to 6 percent of their global revenue.”
II. mastering games of skill with machine learning and deep learning
The goal of AI since its inception has always been to program computers to mimic the human brain as much as possible, and then eventually to surpass its capabilities. Since we are still very much in the learning process as to the functioning of the brain, and computer capabilities continue to improve rapidly, it is inevitable that AI will also evolve over time. All the AI systems that have been successfully put into operation to this date fall into the classification of narrow (or weak) AI. These are programs designed to perform a narrow set of specific functions autonomously, learning often without human intervention to improve performance over time. Narrow AI systems have no way to expand the scope of their functions, however; this can only be done by human programmers applying similar programming techniques to other functions.
The oldest and narrowest of AI applications are programs that exploit the rapid calculations of computers to perform tasks previously taken on by humans, but at much greater speed and efficiency. These are classified as reactive machines; they have no capability to store their results and learn from them how to improve performance. Examples that fit into this category are the first computers to beat human players at chess and Go. IBM’s Deep Blue beat Gary Kasparov at chess in 1997 (see Fig. II.1). Chess is famous for requiring good players to evaluate several potential moves ahead of the one they’re about to make. A computer is able to look further ahead and to evaluate many more possibilities much more quickly than any human. With the aid of custom-built chips to accelerate calculations based on the rigid rules and limited spaces on a chess board, Deep Blue typically searched between 100 million and 200 million potential positions per second, evaluating the probability of improving overall positions for 6 to 8 pairs of moves ahead, and sometimes even up to 20 pairs of moves ahead. Deep Blue did not make any calculations that a human would be incapable of, but it did them orders of magnitude faster, hence looking further into future moves.

The game of Go presents an even greater challenge because the board has 19 x 19 grid points on which players place black and white stones on alternating turns (see Fig. II.2). The object of the game is to place stones to enclose completely and capture more opponent’s stones and area on the board than your opponent. The game ends when one player resigns or both players decide they see no advantage in using further stones. A typical game among experienced players may last about 150 moves. Given the simple rules of the game, there are approximately 10170 possible board configurations to consider, so the search and evaluate several moves ahead approach of Deep Blue doesn’t work well in this case. Attempts to play Go with algorithms akin to Deep Blue’s chess evaluations were unable to beat the world’s best human players.

To beat world Go champions, it was necessary to improve the AI software by programming it to learn by analyzing previously played games, both by humans and computers, including by the AI software AlphaGo — developed by the DeepMind British AI research laboratory that was absorbed by Google in 2014 — itself. AlphaGo is thus an example of a higher form of narrow AI, known as limited memory AI. Essentially all present-day AI applications fall within this category, and apply techniques known as machine learning. In its simplest form, machine learning uses algorithms to train computers via analysis of large datasets to predict desirable outcomes based on a variety of input factors.
For example, suppose that for sports betting purposes you want to predict which young major league pitchers are likely to win one or more future Cy Young awards in either the American or National League. You might create a database containing information on all pitchers who have lasted more than two seasons in the modern history of the major leagues. You include in the database the available data on the pitchers’ first two years of activity: their ages, whether they were left- or right-handed, the teams they pitched for, the catchers they worked with, the types of pitches they threw and their velocities and degrees of motion between the pitcher’s hand and home plate, their injury history, the number of walks and strikeouts they recorded in each season, the number of hits and earned runs they surrendered, the number of games they pitched, won or lost, and so forth. You also include for each pitcher the number of Cy Young awards they won during their entire careers.
Now you divide the database into two parts. The first part is used for training. The AI program determines what combinations of input factors best correlate with the ability to win Cy Young awards in later years; it creates a predictive model. You then allow it to test those predictions on the second part (the testing data) of the dataset to judge its success rate in predicting future Cy Young awards. If you are not content with the success rate, you tweak the algorithms used in training, or you add more types of input data to the dataset (e.g., a third year of data), and iterate. Limited memory AI is not capable of “guessing” which unspecified additional input factors may play significant roles; these must be added by the programmers. The best AI model based on the supplied input data will not reach 100% accuracy because it cannot account for luck or for the far more precise data on pitch spin and movement available only over the past few years. When you have achieved a good model, you may set it loose to predict the future rather than to “post-dict” the past.
The earliest version of AlphaGo trained the computer on 30 million or so Go games (play-by-play sequences of positions for black and white stones) from a variety of internet Go sites, including games played by masters and by computer programs. By analyzing these training games, the program was able to identify a large set of early-game board configurations and to determine sequences of moves following each such configuration that increased the probability of leading to a win. It further calculated the probability increment associated with each move within this very large set of optimal sequences. When AlphaGo was put into competition with Go masters, it then chose moves gleaned from a search through its training analysis data to accumulate the greatest probability of winning. With that approach, AlphaGo was able to defeat very good, but not the greatest, human players.
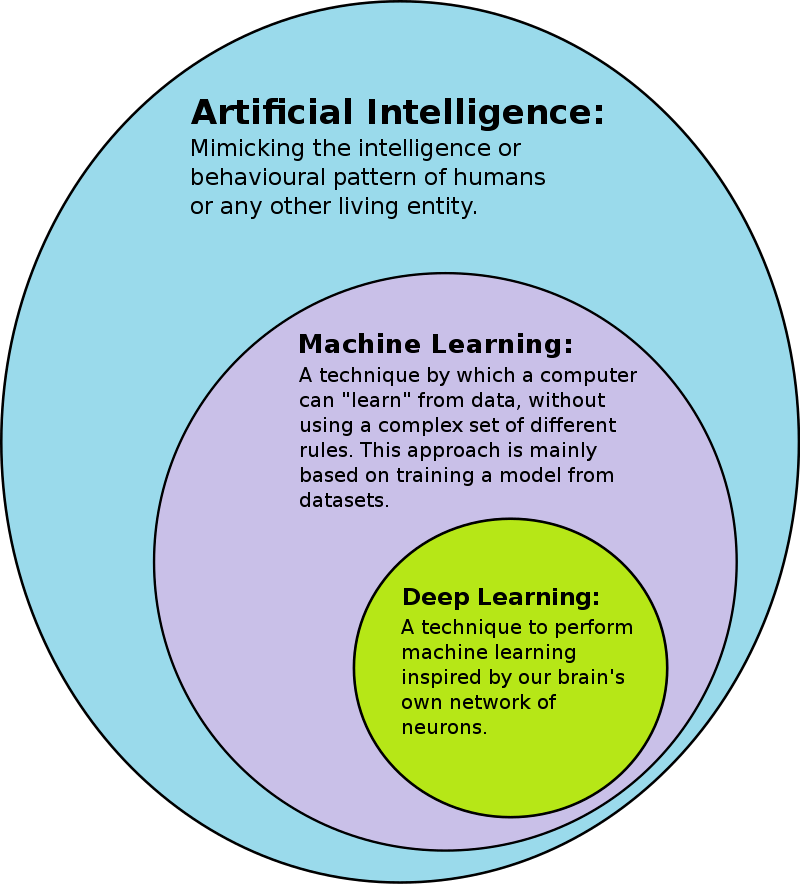
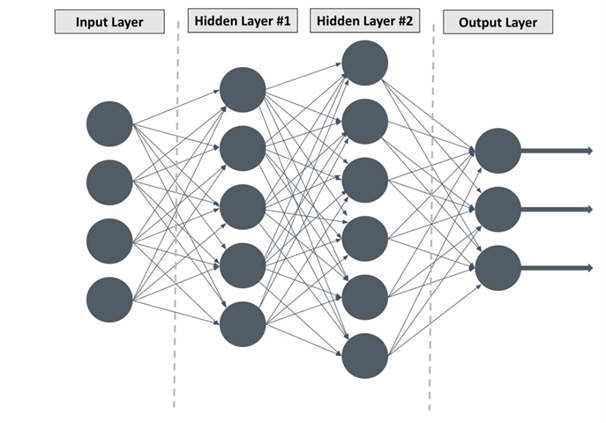
To go beyond this stage, the DeepMind group had to introduce deep learning techniques, using artificial neural networks (ANN) to enhance the learning process. As illustrated in Fig. II.3, deep learning is just an evolved subset of machine learning, which is in turn a subset of AI techniques. The design of ANN are based schematically on the vast network of neurons in the human brain, where perceptions are refined in successive stages via signals carried to different parts of the brain by sequential neuronal connections. A simple deep learning ANN is illustrated in Fig. II.4.
ANN and deep learning techniques are used, for example, in nuclear and particle physics “needle-in-a-haystack” searches for rare events among billions or trillions of particle collision events recorded by complex detectors. The detectors provide a substantial set of measurements characterizing each recorded event and the deep learning algorithms must decide the optimal way to combine all those measurements to reveal the desired rare events. In such cases the training data includes simulations of the rare events of interest, embedded within simulated or actually measured backgrounds of the far more abundant events generated in the studied particle collisions. Deep learning techniques have become feasible mostly within the past decade as computing power and storage have vastly increased with the emergence of cloud computing and high-speed graphical processing units (GPUs).
When the programmer provides the large datasets used for training machine learning algorithms, the situation is described as supervised learning or human-in-the-loop. However, in applications to games such as chess or Go, that have well-formulated rules, AI algorithms can also learn through unsupervised learning. AlphaGo was greatly improved when its initial supervised training was later reinforced by unsupervised learning developed from many games the computer played against amateurs and finally against other versions of AlphaGo. Especially when playing against itself, AlphaGo was able to try unprecedented moves, of types not seen in all the human games on which it was initially trained, and to determine their probability of leading to a win.
Then, according to the summary on the AlphaGo website: “In October 2015, AlphaGo played its first match against the reigning three-time European Champion, Mr Fan Hui. AlphaGo won the first ever game against a Go professional with a score of 5-0. AlphaGo then competed against legendary Go player Mr Lee Sedol, the winner of 18 world titles, who is widely considered the greatest player of the past decade. AlphaGo’s 4-1 victory in Seoul, South Korea, on March 2016 was watched by over 200 million people worldwide. This landmark achievement was a decade ahead of its time. The game earned AlphaGo a 9 dan professional ranking, the highest certification. This was the first time a computer Go player had ever received the accolade. During the games, AlphaGo played several inventive winning moves, several of which…were so surprising that they upended hundreds of years of wisdom. Players of all levels have extensively examined these moves ever since.”
After losing to AlphaGo, world master Lee Sedol said “I thought AlphaGo was based on probability calculation and that it was merely a machine. But when I saw this move, I changed my mind. Surely, AlphaGo is creative.” But this is not the form of creativity we normally associate with a sudden burst of inspiration or novel insight occasionally experienced by gifted humans (think of Albert Einstein developing the theory of relativity after imagining, as a teenager, chasing after a beam of light). AlphaGo’s “creativity” is gleaned by being able to play the game an enormous number of times – a game that might take humans hours to complete can be played in seconds by computers – and to try out unusual moves and see where they lead. AlphaGo has superhuman experience, calculation speed, and memory focus – these are the advantages of AI — rather than superhuman insight or intuition.
In 2017 the DeepMind team unveiled AlphaGo Zero, a new AI algorithm that was given no supervised training. The rules of the game and the layout of the game board were programmed, but from those constraints the AI program underwent deep learning by playing exclusively against itself, starting from completely random play. This approach parallels how most humans learn the intricacies of a new game, and the strategies that work best, but AI does it at warp speed. As the DeepMind team put it: “…the computer program accumulated thousands of years of human knowledge during a period of just a few days and learned to play Go from the strongest player in the world, AlphaGo. AlphaGo Zero quickly surpassed the performance of all previous versions and also discovered new knowledge, developing unconventional strategies and creative new moves… These creative moments give us confidence that AI can be used as a positive multiplier for human ingenuity.” In the years since, DeepMind has applied the same techniques successfully also to mastering chess and shogi (a Japanese cousin of chess), in AlphaZero, and visually complex Atari games, without even being given the rules of the game, in MuZero.
III. image recognition
Deep learning algorithms are also used to great effect in image recognition AI. For example, you might want to train a computer to recognize and label different animals from visual scans of their images. The training data for elephants, say, may consist simply of many photographs containing elephants viewed from a variety of angles. The ANN then formulates a progressively improving set of curves that, when assembled together, form the unmistakable outline of an elephant, as illustrated in Fig. III.1. The same pattern recognition approach can then be used for different animals – e.g., a penguin or a kangaroo, as suggested in the figure.
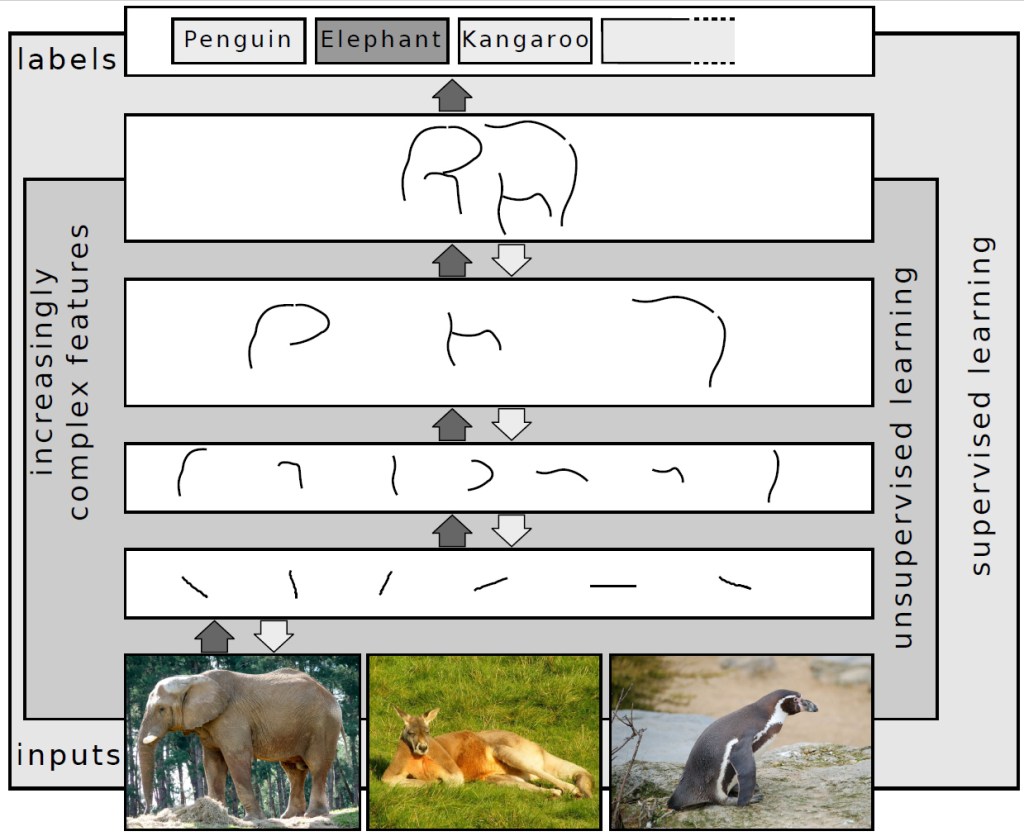
The speed at which the image recognition software can be trained on other animals can be greatly accelerated by the addition of transfer learning, adapting learned strategies and curves found to be useful in the elephant example as starting points for the training on penguin or kangaroo photos. Transfer learning is defined as “the improvement of learning in a new task through the transfer of knowledge from a related task that has already been learned.” Humans make use of transfer learning as a matter of course, e.g., accelerating the mastery of motorcycle riding if the user has already mastered bicycle riding, or solving new problems by analogy with different problems previously solved. As illustrated in Fig. III.2, transfer learning is then a method to make narrow AI slightly less narrow in focus by relaxing the normally heavy demands of deep learning on the size of training datasets and on computational power.
Deep learning image recognition AI is the heart of facial recognition programs. It is one thing to train a computer to recognize human faces in general, but a far more difficult task to distinguish individual humans (e.g., to identify criminal suspects or intended recipients of private access to information or restricted areas, or to substitute for passwords for computer access), whether seen alone or in a crowd, in a photo or a video, in color or black and white.
The distinctions in facial features among distinct humans are, of course, much more subtle than the distinctions between elephants and kangaroos. Facial recognition programs typically determine skin tone and the shape of eyes, irises, eyebrows, nose, mouth, nostrils, chins, and overall facial structure (see Fig. III.3), and must pick out faces even when hair is covered and eye color is possibly affected by contact lenses. And the potential hazards of applying facial recognition too widely – e.g., violations of privacy, training data biases that lead to racial profiling in identifying suspects, unlawful surveillance – are important to consider and tricky to defend against. Nonetheless, many companies are currently investing in facial recognition development and the current state-of-the-art seems to be attainment of about 99.5% accuracy in matching observed faces to ones stored in a large database, or scanned faces to passport photos in passport control at many worldwide airports.

IV. self-driving cars
Deep learning image recognition is also a critical feature in the applications of AI to produce self-driving cars. A self-driving car (Fig. IV.1) is outfitted with a variety of sensors – “optical and thermographic cameras, radar, lidar [laser imaging, detection and range determination], ultrasound/sonar, GPS, odometry, and inertial measurement units” – to mock up human sensory perceptions. It must use and analyze data from all these sensors to identify objects along its path – traffic signs, pedestrians, other vehicles, obstacles on the road, etc. – as well as traffic delays along paths from the starting point to the desired destination, in order to guide its navigation, select its speed, respond to traffic, and protect its own passengers, as well as those in other vehicles. It must also control vehicle hardware associated with acceleration, braking, steering, and signalling. In addition to sensing external conditions, a self-driving car must monitor internal hardware conditions within the vehicle – fuel level, engine temperature and health, tire pressure, oil pressure, etc. – to anticipate mechanical problems.

The AI software to accomplish all these tasks is still considered an example of limited memory narrow AI, but it represents a far more ambitious, and far riskier, broadening of scope in comparison with game-playing or even facial recognition. A self-driving car must rapidly distinguish whether an object sensed ahead in its path is a crossing pedestrian, a leaping deer, a car changing lanes, or a stationary object likely to cause damage to the vehicle in a collision, and it must do so in daylight, at night, in the presence of dense fog or blinding sunlight, and in all sorts of storms. It must also distinguish between different types of road signs and adjust its speed and path to obey them. At the same time, it must respond to voice commands given by human passengers, who may alter the destination or suggest alternate routes. And, most challenging of all, it must learn to react appropriately to unforeseen dangers that appear suddenly. Each of these many tasks must rely on AI software in addition to reliable hardware.
A few of the necessary features along the path to autonomous vehicle operation are already incorporated in the safety systems of many cars sold today: e.g., lane assist technology to correct steering if needed to keep a vehicle within its lane; automatic emergency braking to avoid or mitigate sensed impending collisions; adaptive cruise control that adjusts speed to maintain safe distances from vehicles in front of you; automated parallel parking. Such systems already register within the classification of automation levels codified by the standardization organization SAE International. This classification defines five levels of potential automation:
- Level 0: The automated system issues warnings and may momentarily intervene but has no sustained vehicle control.
- Level 1: “hands on” — The driver and the automated system share control of the vehicle. When the contemporary safety systems listed above are activated, the vehicle is considered to be at this level.
- Level 2: The automated system takes full control of the vehicle: accelerating, braking, and steering. The driver must monitor the driving and be prepared to intervene immediately at any time if the automated system fails to respond properly. This level is sometimes referred to as “hands off,” but that nomenclature is misleading, because the human driver is required to be at least ready to take over control at any moment, and in some cases may be required to keep hands on the steering wheel at all times and, if the vehicle is outfitted with appropriate sensors, to keep eyes on the road.
- Level 3: “eyes off” – the human driver is considered a co-pilot who may divert attention from the road while the automated system controls acceleration, braking and steering. However, the driver must still be prepared to intervene within some limited time, specified by the manufacturer, when called upon by the vehicle to do so.
- Level 4: “mind off” – a human driver must be present in the vehicle, but need not pay attention while the automated system fully controls the driving. An example would be a robotic taxi or a robotic delivery service that covers selected locations in an area, at a specific time and quantities. Automated valet parking is another example.
- Level 5: “steering wheel optional” – no human driver is required to be in the vehicle; the automated system will never need to ask for an intervention. An example would be a robotic vehicle that works on all kinds of surfaces, all over the world, all year round, in all weather conditions.
There is not currently any vehicle available for commercial sale in the U.S. at level 3 or above. There are, however, driverless taxi rides available to the public, from Waymo (previously known as the Google Self-Driving Car Project) in parts of Phoenix, Arizona and from Cruise in San Francisco (where navigating steep hills with limited visibility near the peaks must present a particular challenge for sensors, as for humans). There are autonomous commercial delivery operations available in California. And Honda and Mercedes-Benz have received approval for level 3 commercial cars; so far, the Honda version is available for lease only in Japan. The global market for autonomous vehicles is expected to reach $60 billion well before 2030.
But there is by now a significant testing history available for driverless vehicles thanks to research funding and grand challenges available for many years from the U.S. Defense Advanced Research Projects Agency (DARPA), from Mercedes-Benz, and from Bundeswehr University Munich’s EUREKA Prometheus Project. This research led to some notable achievements: in 1995 an autonomous car designed by a group from Carnegie-Mellon University completed a nearly 3000 mile trip from Pittsburgh, Pennsylvania to San Diego, California with autonomous driving for 98% of the trip; in 2015 an Audi augmented with Delphi technology covered 3400 miles through the U.S. with 99% in self-driving mode.
As a counterpoint, however, there have also been some serious incidents and accidents with Level 2 vehicles whose drivers have placed too much trust in their autonomous modes. Tesla has outfitted its cars since September 2014 with an AutoPilot system intended to take over control of the vehicle when a human driver considers it safe to do so. In May 2016 Joshua D. Brown of Canton, Ohio became the first person to die in a self-driving car when he placed too much faith in his Tesla AutoPilot system. As told by Meredith Broussard in her book Artificial Unintelligence, “It was a bright day, and the car’s sensors failed to pick up a white semi-tractor-trailer that was turning through an intersection. The Tesla drove under the truck. The entire top of the car sheared off.”
Unfortunately, Tesla’s CEO Elon Musk is a hard-headed executive who is too willing to override his own engineers when it comes to the design of autonomous vehicle systems. In October 2020 Tesla started a Full Self-Driving (FSD, though still Level 2) capability beta program in the U.S. that has attracted 360,000 participants. But that year Musk also decided, over his engineers’ strong objections, to eliminate radar sensors from Tesla cars starting in 2021, and to disable radar in the company’s earlier vehicles. While his decision was presented as a cost-saving measure, Teslas had previously eliminated lidar sensors, and Musk wanted to develop self-driving cars that relied only on cameras, to provide a close mock-up of human driving.
According to a story in the Washington Post, “The result, according to interviews with nearly a dozen former employees and test drivers, safety officials and other experts, was an uptick in crashes, near misses and other embarrassing mistakes [such as random sudden braking when the car sensed non-existent obstacles] by Tesla vehicles suddenly deprived of a critical sensor. “ Musk seemed content to let the beta system customers debug the FSD mode, despite safety concerns. “Customer complaints have been piling up, including a lawsuit filed in federal court last month claiming that Musk has overstated the technology’s capabilities. And regulators and government officials are scrutinizing Tesla’s system and its past claims as evidence of safety problems mounts, according to company filings.” In February 2023, all the Tesla vehicles equipped with FSD beta were recalled by the U.S. National Highway Traffic Safety Administration and addition of new participants was halted by the company.
Even without bone-headed management decisions, self-driving cars at Level 3 and above are inherently dangerous, and perhaps a bridge too far for AI applications, no matter how well-tuned the image recognition software may become. Drivers with modern vehicles outfitted with many computer-controlled systems have a sense for how often software bugs or hardware glitches cause problems requiring repair, despite the fact that such systems do improve safety overall. It seems unreasonable to rely on AI and hardware alone to replace an alert human’s defensive driving capabilities in unforeseen conditions. Will AI be programmed to anticipate dangerous or unlawful sudden actions of other drivers sharing the road? Will it handle rapidly changing light and weather conditions? During the first decade of this century, I was driving my son’s family to the Oakland airport to catch a flight, when one of my tires suddenly blew out on a highway in moderately heavy, but fast-moving traffic. I was able to respond quickly and to steer the car, with a shredded tire and emergency flasher turned on, safely through two lanes of oncoming traffic to the nearest shoulder to replace the tire. Would a self-driving car manage to accomplish the same feat?
Human drivers, especially distracted or drunk ones, may well make more frequent mistakes than eventual autonomous systems, but that will offer scant solace to the victims of AI or associated hardware failures. On the other hand, in a long-range future one can imagine the majority of traffic to involve self-driving cars that communicate with each other (although not with leaping deer or unwary pedestrians) to smooth traffic flow substantially, and thereby reduce accident frequency. But with most cars communicating through some common network, the software becomes more susceptible to hacking to wreak havoc on roads. Even well before computers control all vehicle operations, a group of security researchers has recently revealed vulnerabilities in many of today’s cars, allowing hacks to take over control of car functions or to start or stop the engine.
One ethical issue that has been discussed extensively with regard to self-driving cars concerns the so-called “trolley problem.” In the context of autonomous vehicles, the trolley problem may be stated this way: suppose the car must veer from its narrow path in heavy traffic when it senses a serious obstacle ahead; but if the car veers right it will likely hit three young people waiting at a bus stop. If it veers left, it will likely strike a large tree, threatening the life of the driver and passengers. What path should be chosen? Narrow AI has no free will; it can only make choices that are programmed in by the developers. For example, an article in the business magazine Fast Company reported that Mercedes engineers planning for eventual level 4 and 5 self-driving cars will program their software to always work to save the driver: “Instead of worrying about troublesome details like ethics, Mercedes will just program its cars to save the driver and the car’s occupants, in every situation.” This is the type of rare situation where a human driver capable of rapid evaluation may work to find an alternative to the two terrible options considered by self-driving AI.
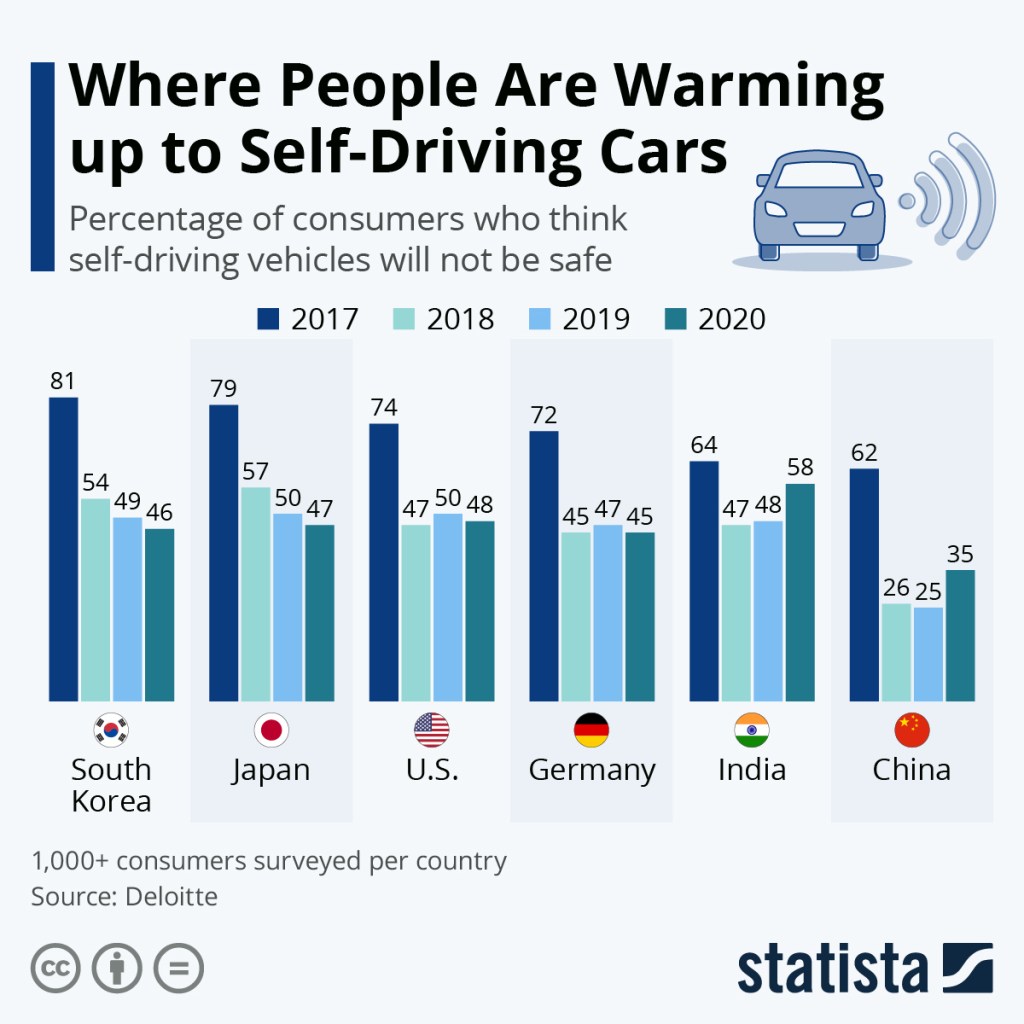
In a 2016 conversation about self-driving cars between President Barack Obama and MIT Media Lab Director Joi Ito, Ito said: “When we did the car trolley problem, we found that most people liked the idea that the driver and the passengers could be sacrificed to save many people. They also said they would never buy a self-driving car.” In fairness, consumers worldwide have grown somewhat less wary about the safety of self-driving cars since that conversation (see Fig. IV.2). But the attitude expressed by the majority in Ito’s sampling pretty much sums up where I am personally, not strictly because of the rather contrived trolley problem, but rather because AI is still a long way from being able to react like a human to unforeseen problems not previously encountered, and such problems arise with appreciable frequency when sharing roads with other drivers and living things. In addition, commercial companies have been known frequently to cut safety corners in the pursuit of bigger profits (hello, Mr. Musk), often with disastrous results. The Mercedes response also highlights another general feature of AI: it will almost always embody some biases, either conscious or subconscious, of the programmers who decide how it reacts and what data it is given to train on.
— To Be Continued in Part II —
